
An assistant that improves
with every interaction
Your current assistant “learns” through system prompts and context tricks. CLaaS is an open-source prototype that turns interactions into weight updates, personalizing and improving your model over time.
Don't have a GPU? Sign up for updates on our hosted solution.
The learning gap
In-context learning doesn't scale. Every preference, instruction, and memory stuffed into your prompt is a token your assistant can't spend on the task that actually matters.
Base model
Every conversation starts from scratch.
Prompting and memory
The context window gets filled with system prompts and memory files. But it’s reminding, not learning.
Continual Learning
Your feedback changes the model weights themselves, rewiring how it thinks. No context overhead. No forgetting.
How it works
Every conversation makes it smarter
Base Model

After CLaaS

01Chat naturally
Use your personalized assistant on Telegram with an open-source model you control.
02Give feedback
Give text feedback on any response to teach and improve the model.
03Real-time weight update
Your feedback is distilled into weight updates. Your assistant improves without forgetting.
04Better every message
Your next response comes from an updated assistant that’s slightly more yours.
Features
Your model, your infrastructure
Fully open source
Run entirely on open-source models you control. Your data stays on your infrastructure with no external API dependency.
Learns per-request
Every API call updates the model without redeployment. Your model evolves with each interaction in real time.
Telegram integration
Give feedback directly in your Telegram chat. Each piece of feedback triggers a model update in real time.
Flexible deployment
Single consumer GPU, Tinker SDK (no GPU), or Modal cloud. Docker Compose gets you running in minutes.
Hosted solution
No GPU needed. We run CLaaS on our secure infrastructure so you can personalize your assistant with zero overhead.
Implicit feedback
Every chat message and tool use is a training signal. Your assistant learns from how you interact, no explicit feedback needed.
Training Dashboard
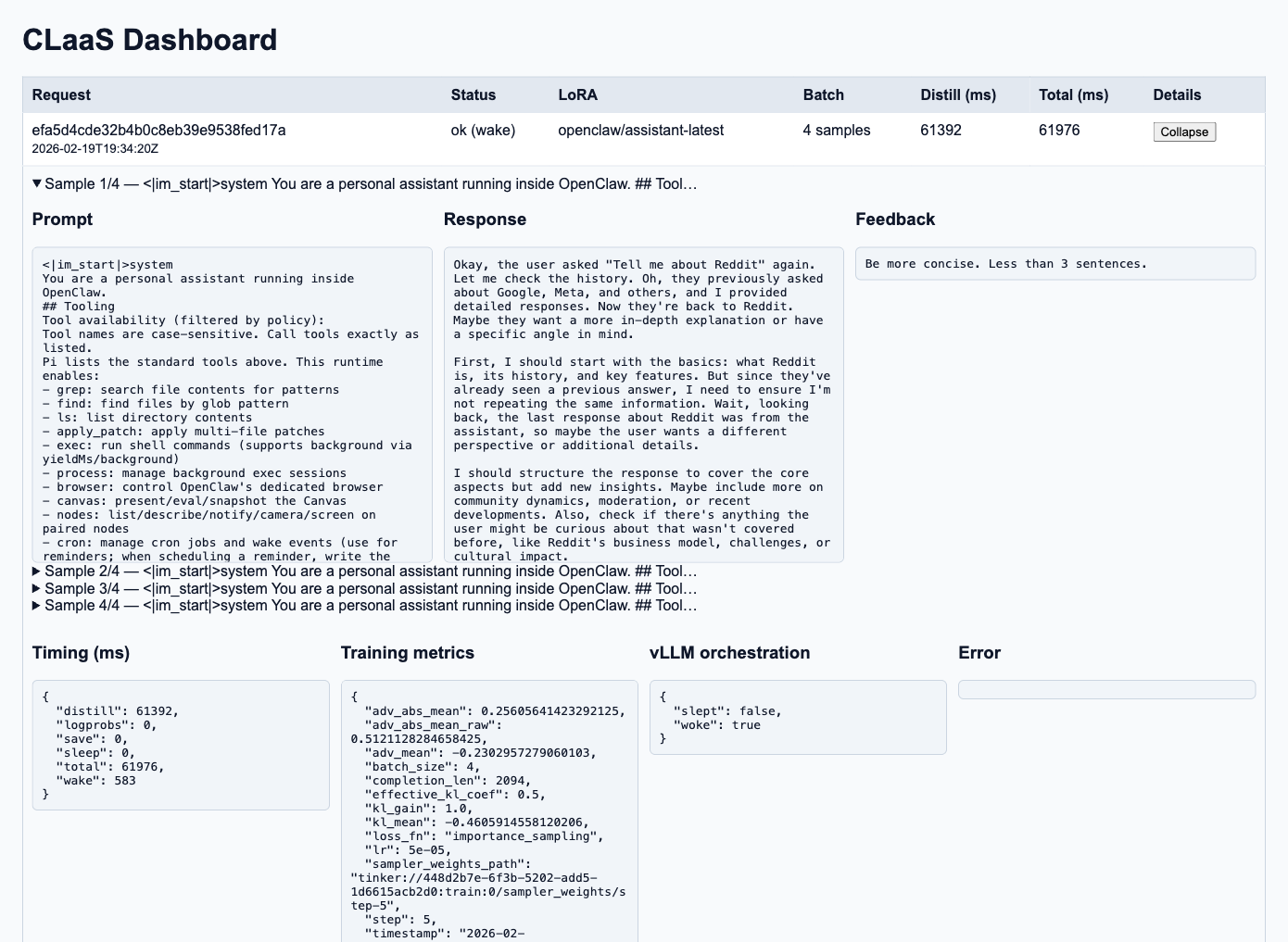
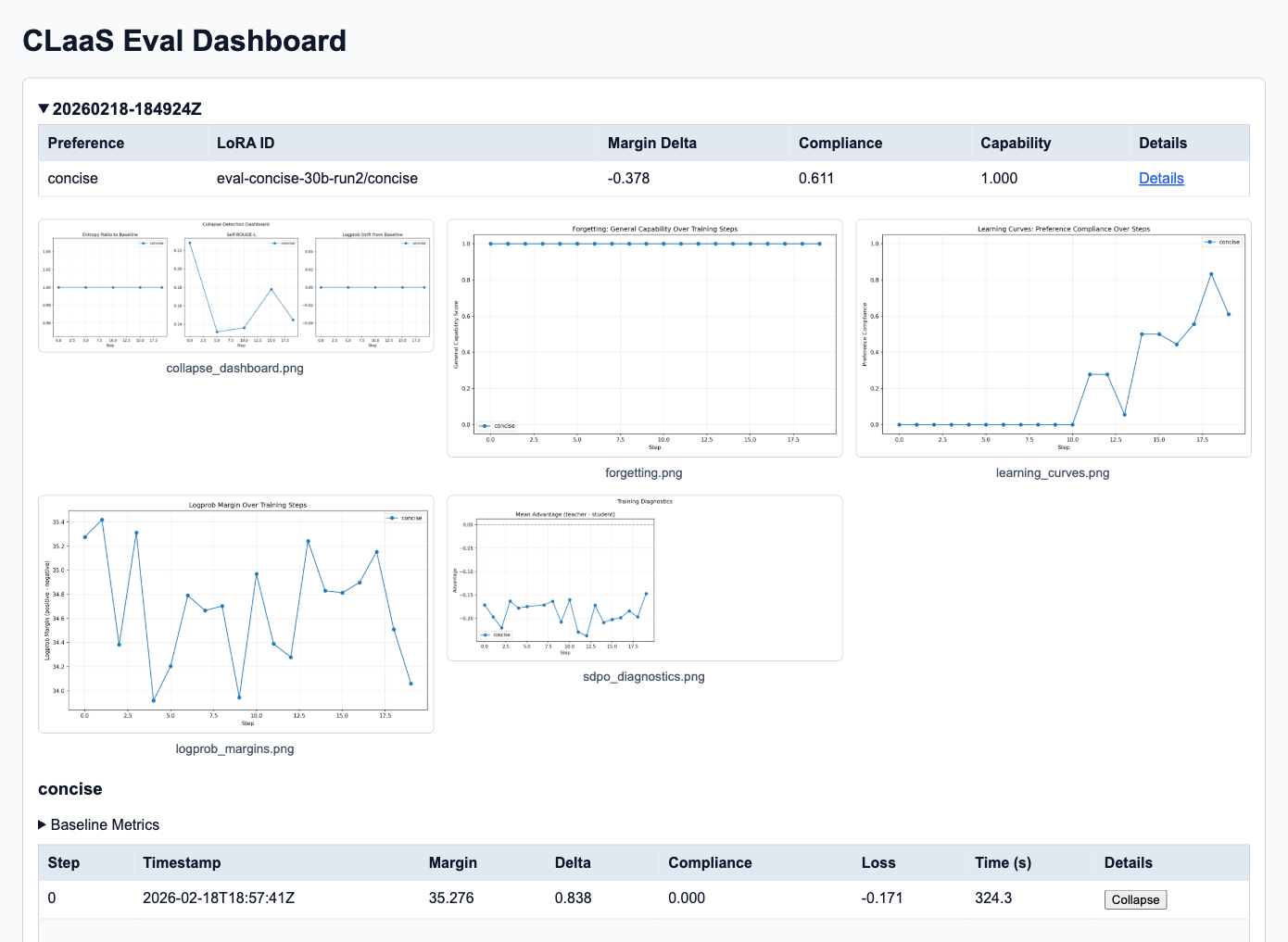
Eval Harness Dashboard
Architecture
Hybrid engine for local deployment
Local deployment alternates between a serving and training state.
vLLM inference
- ›Route traffic through vLLM
- ›Low-latency generation with LoRA
- ›Hot-reload updated adapters
Self-distillation
- ›Pause serving to free GPU memory
- ›Single distillation step on adapter
- ›Learn from feedback without forgetting
Flexible backends
- ›Local GPU (single consumer GPU)
- ›Tinker SDK (no GPU required)
- ›Modal (coming soon)
Don't want to self-host?
We're building a hosted version of CLaaS: a personalized assistant that learns from you, running on our infrastructure. No GPU required.
Join the waitlist to get early access.